Inside DigitalOcean's Reserved IP Rails migration | DigitalOcean
Julius Zerwick
Reserved IPs (formerly named Floating IPs) is one of our oldest products, and it has changed little since its launch in 2015. As DigitalOcean grew over the years and more customers adopted Reserved IP as a High Availability solution, we started experiencing growing pains, and scaling Reserved IP was critical for continued success. Last year, we were able to prioritize an initiative to overhaul our Reserved IP stack and embarked on a journey that aimed to address various issues for customers and internal teams, ranging from improving the performance and stability of the Reserved IP stack to reducing its maintenance overhead.
The issues we addressed comprised three different areas:
- Lack of the ability to scale Reserved IP software stack as the usage grew
- Increase in customer bugs and reports due to an ill-defined distributed workflow which caused operational and maintenance overhead on the engineering team.
- This also hindered our need to enhance this legacy product to open the doors to new features for our customers.
- Other DO products that use Reserved IP as an underlying system were not able to scale accordingly
The Reserved IP logic was scattered throughout our architecture from the product level down to the hypervisors where events are scheduled. The scattered logic, coupled with a multitude of microservices in-between, resulted in a very distributed workflow. This was the cause of many bugs and customer reports, adding to operational issues for our customers. These continued problems left our team consistently spending time putting out fires.
The legacy Reserved IP tech stack (Rails apps, MySQL cluster, Perl running on the hypervisors) made feature development and improvements slow. There was a lack of fine grained observability and independent scalability, as well as friction for integrations that caused internal product teams to make external calls for Reserved IP operations through the customer facing Public API rather than internal to our system.
Background
Reserved IPs (FLIPs) allow customers to have a dynamic IP address that they can easily reserve to their account, assign to a Droplet, reassign to a different Droplet in the same data center, and ultimately release back into our pool of available Reserved IPs. This enables our customers to create a more highly available system architecture and minimize downtime.
As an example, imagine a Reserved IP assigned to a Droplet that is running a load balancer which is fielding all requests to your backend system. With some scripting and config, you could arrange for a secondary load balancer to run in a passive setting while sending health check requests back and forth with the primary load balancer. If the primary load balancer ever fails its health check, you could easily failover to the secondary and reroute traffic by assigning the Reserved IP to it.
In DigitalOcean’s internal system, the logic for managing Reserved IPs was located in a pair of legacy Rails applications: one for our web UI called Cloud given that a user’s account page was at cloud.digitalocean.com and another for our Public API called API. Both of these apps contained some shared logic for handling customer requests for Reserved IPs while also having some nuanced differences. The shared logic would include updating the state of a Reserved IP and inserting events in our shared MySQL cluster used by the majority of our internal services, as well as emitting events to a Kafka cluster to update the billing state of a user’s Reserved IP.
This architecture worked well for many years, but as time went on it became apparent that there were several issues we needed to solve:
- In the years following the release of Reserved IP, DigitalOcean’s engineering teams moved away from using Ruby/Rails and toward Golang for improved system performance and the benefits of static typing.
- As a result, the number of engineers with strong Ruby/Rails skills diminished over time which made it very difficult to maintain and improve these Rails applications.
- The size of our customer base had grown massively over time and the Rails apps had become a bottleneck on how quickly we could serve user requests.
- The Rails apps contained logic for many of our products like Droplet and Load Balancers, and as our services grew we wanted to extract this logic out into separate microservices owned by different teams.
- Several race conditions with Reserved IPs had been identified in our system architecture that originated in the Rails applications and would best be tackled by rewriting much of the logic into new services.
With these problems to solve, our team scoped and designed a migration project to build a new set of microservices able to handle all of the Reserved IP logic that lived in the Rails apps.
New architecture
After several iterations of our proposed design for the new architecture, we settled on introducing two Go microservices that would have a clear separation of concerns between logic needed to manage the state changes of Reserved IPs and logic needed to handle the user request, gather information from other internal services, and craft the response back to the user.
The first microservice is an orchestrator service that manages the Reserved IP state whenever a user reserves an IP, assigns it to one of their Droplets, unassigns it from a Droplet, and releases it from their account. This state management involves three key components:
- Updating the Reserved IP’s state stored in our shared MySQL database cluster
- Inserting an event into the same database cluster that is used to track the Reserved IP update by other internal services; an example would be services that need to modify the networking config of a Droplet if a Reserved IP was assigned to it
- Emitting an event to a shared Kafka cluster for updating a user’s billing status depending on the update to their Reserved IP
The second microservice is an aggregator and its responsibility in the stack is to receive the incoming HTTP request from a user, parse the request and data, make gRPC requests to any other necessary internal services to retrieve information on the Reserved IP, and then package the data from these responses into a HTTP response. Thus, it “aggregates” all the data needed in the response to the user.
At a high level, these two microservices handle the same responsibilities as the legacy Rails applications but with some noticeable improvements:
- The top-level request handling logic that was once tightly coupled with the internal Reserved IP operations has now been decoupled into separate services for more efficient development, maintenance, and scaling to meet increased user traffic.
- We’re now able to leverage a host of internal Go packages including end-to-end tracing of requests through our system and logic to retry internal operations that failed due to transient issues.
- We can now easily integrate with other internal services using gRPC as part of a larger effort within DO engineering to modernize our system and remove single points of failure.
- The response time of user requests for Reserved IP operations decreased dramatically with reductions of over 50 - 80%.
Here’s a high-level diagram of how these two microservices fit into our larger system:
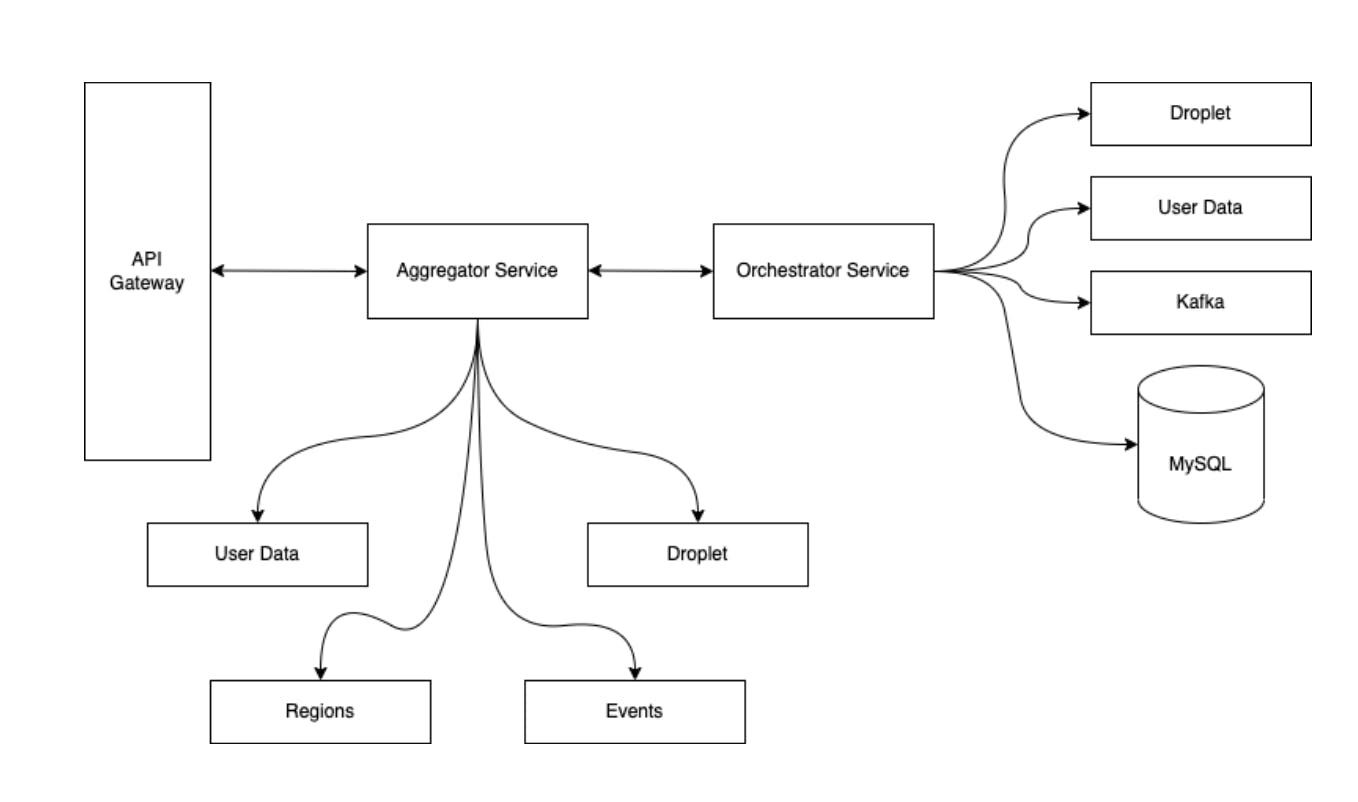
The reward was truly worth the effort, and it required a lot of care in planning, design, development, and rollout to production.
Development and Rollout Process
Given the scale of this project, our team took a step-by-step approach to minimize any impact to our customers. The initial phase was largely spent on understanding the legacy Rails applications, including its design, API, common failure modes, and integrations with other services in our system. The time we spent here was crucial to establishing a firm foundation for the rest of the project, given that the legacy applications hadn’t been actively maintained by a team for a lengthy period of time and existing documentation was minimal. Taking the time to explore and document our learnings before considering the design of our new architecture ensured that we would take into account various edge cases, user behavior/expectations, current performance metrics, and quirks when we began development.
Once we had mapped out the existing code paths for the various Reserved IP operations, we began the development of our new architecture using a cyclical process that we followed for each code path. The steps were as follows:
- Write a short design document detailing the proposed code to rewrite an existing Reserved IP operation into Golang. For example, users can reserve a Reserved IP to their account so the reserve code path had its own design document.
- Collect feedback from our team on the design and address any concerns, missed details, or questions.
- Begin implementing the design, which would involve writing code for both the aggregator and orchestrator services. This included writing unit tests and performing manual tests of mocked requests to a running instance of our new code.
- Once all development of the code path was complete, write up a test plan containing a list of end-to-end test cases to perform once the changes were deployed to our staging or production environment.
- Our deployment pipeline first deploys to a staging environment, and then we can manually deploy to our production environment. We first deploy to staging and run through our test plan to discover any bugs, then let the deployment “soak” in our staging environment for some time.
- Deploy the changes to production behind what’s known as a “feature flipper,” which allows us to control the amount of user traffic to send to the new microservices, starting with 0% of traffic.
- Then incrementally redirect increasing amounts of user traffic away from the legacy Rails applications and to our new microservices.
In total, we had 18 code paths that needed to migrate to our new architecture. While it may look time-consuming, we extracted many benefits from designing, developing, testing, and rolling out each code path individually because it was then easier to uncover and address any bugs we found. This process also ensured customer impact would be minimal with each migration.
An important part of our process was the use of a “feature flipper” to control the amount of traffic that was directed to our services. A feature flipper can be thought of as a gate or filter for requests entering certain code paths in a system. You can use a feature flipper to completely block any requests from exercising a code path and then, with a small config change, remove the block incrementally or all together.
At DigitalOcean, we have feature flippers built into our Edge Gateway, a service that receives all external traffic sent to our system routes them to the correct internal services, and then returns the response to the user that sent each request. It’s similar in concept to an API gateway.
With a little configuration, it’s easy for us to define a feature flipper in the Edge Gateway that allows us to dynamically change the amount of user traffic that is redirected away from the legacy Rails apps and toward our new microservices stack. Our current options for setting our feature flippers include:
- Selecting a group of users will be redirected based on their user ID; this is very helpful for allowing production changes to be tested by internal users like our team before enabling actual customers.
- Selecting a percentage of all users hitting our endpoints; allows us to slowly roll out changes to our users over a period of time and thus minimize the impact of any bugs or regressions in our code.
Whenever we were ready to test a new code path in production, we simply enabled just the user IDs of our team members, went through our test plan, and then gradually enabled an increasing number of users each day to exercise our new stack while also moving them off of using our legacy Rails apps.
These feature flippers also enabled us to have a faster response in the case of any problems discovered with our new code paths. Instead of needing to perform a “rollback” by deploying an older version of our code, we could simply turn the feature flipper off, and then all users would go back to using the established legacy apps. This significantly reduced any downtime that our customers experienced and provided a fast mitigation strategy that our operations team could perform without needing to page our on-call team member.
Impact of New Architecture
After several months of work, our team completed the migration project and routed 100% of user traffic for Reserved IP operations to the new architecture. The immediate impact on our metrics was a dramatic decrease of 4 - 10x in our response times which directly resulted in a faster user experience. We also noticed a decrease in our internal error rates as our new architecture more gracefully handled errors and allowed for retrying internal operations that could transiently fail.
Aside from improvements to our metrics, our new architecture also improved the overall performance of other products that use Reserved IPs in their underlying architecture. The internal services managing these products used to make requests that traveled out of our internal system and through our Public API, which added to the overall latency of their operations. With our new architecture that provided a gRPC API for internal services, these other services could switch to calling this API directly, which cut their response times in half.
The new architecture improved the reliability and scalability of the Reserved IP stack in our system as a consequence of decoupling the legacy logic into two microservices that could be scaled independently. We also implemented techniques to gracefully handle internal errors that might be transient and retry them using exponential backoff. This made our system more robust in the face of any hiccups that the system might experience day-to-day.
Finally, the migration from Rails to Go led to a boost in our team’s developer productivity. Most members were more experienced with Go and were able to leverage existing tools and patterns that weren’t applicable to the Rails apps. This meant that we were able to address customer issues, bugs, and performance fixes more quickly and efficiently than before.
Challenges & Learnings from this Project
This is one of the larger projects our team has taken on and took several months to complete. Along the way, we encountered several challenges that provided valuable learnings for future projects.
Put more time upfront in discovery and documentation
One of the biggest challenges we faced with this project was the lack of internal documentation on Reserved IP operations, what dependencies existed with other internal services or products, edge cases with user requests to the API, and more. This lack of documentation and existing knowledge at the company as engineers left over the years led us to spend a lot of time upfront on discovery and writing documentation. We needed to know all of these details in order to properly design, develop, and test the new code paths without any regressions in existing operations and user experience. While discovery and documentation might not be the most “fun” part of the process, it ended up being one of the most valuable as the knowledge gathered during this time led to our system requirements and ultimate designs and ultimately saved time and development pain in the later stages of the project.
Strive to have an exhaustive test plan
When it comes to migrating an existing product, it’s vital to ensure that you have a test plan to cover all of the known “happy path” cases, common failure cases, and edge cases to gain confidence that your new architecture supports the same features and use cases as before. The “happy path” cases cover successful executions of the code and ensure that existing functionality still works between the legacy and new architectures. The common failure cases cover any requests/inputs that will result in the system returning a known error. It’s important to preserve these common failure cases as users of the system will depend on them just as much as your happy path cases. Lastly, the edge cases are tests that cover any possible requests that might appear strange or unlikely but could still occur and negatively impact your system. While it may seem tedious and unnecessary to create such a rigorous test plan, the payoff is immense in the amount of time and customer impact saved from catching bugs ahead of time before they land in production.
Capture important metrics before and after
It’s important to know what the vital metrics for your service/project are and which ones you’re expecting will improve by the completion of your work. This will allow you to make data-driven decisions so that you can spend design and development time on the areas that will make the biggest impact. Additionally, these metrics will provide valuable feedback on what improvements were made to the system. Unless you have datasets to compare against, you can’t state with confidence what improvements were a result of which efforts in your work, i.e. “Completing X led to Y results”. Lastly, having this data on hand also enables you to share your achievements across the wider organization to show that the project was a success and worth the resources spent on it. You can also use this data in conference talks or online articles that detail your work and the improvements it made to your company’s system and customers, which can have an incredibly positive impact on your career.
Preserve the existing API
When working on a migration project that exposes an API used by internal services and/or customers, it’s of the utmost importance that you preserve the existing API as much as possible. Performing any breaking changes without properly thinking them through, communicating them to your users ahead of time, or maintaining backwards API compatibility will lead to a poor customer experience that should be avoided. There is certainly a time and place for public/external API changes, but coupling it with a migration between architectures is very risky. That said, consider changes to any internal API changes, i.e. endpoints in your service that are only used by other services in your internal system, as it’s much easier and faster to get other teams to update their code to use the modified or new API rather than customers.
Conclusion
Our team successfully migrated the tech stack for our Reserved IP product from our legacy Rails applications to a new set of Golang microservices. By using a rigorous cycle of design, development, testing, and rollout steps we were able to complete this migration with minimal impact to our customers. At the same time, we gained large improvements to the system’s key performance metrics and our team’s productivity.
Interested in building the cloud at DigitalOcean? Check out our careers page for openings on our teams!
Related Articles

Transforming Data Protection: Unveiling Faster, More Reliable Backups and Snapshots
Jawaad Tariq, House Li, Urchin Colley , Jenni Griesmann, and Archana Kamath
May 15, 2024•5 min read

